Chenyang Si
Assistant Professor
Nanjing University
Email: chenyang.si.mail@gmail.com
chenyang.si@nju.edu.cn




Biography
I am a Tenure-Track Assistant Professor at the School of Intelligence Science and Technology, Nanjing University. Prior to this, I was a Research Fellow at Nanyang Technological University (NTU), Singapore, working with Prof. Ziwei Liu. Before that, I worked as a Research Scientist at the Sea AI Lab of Sea Group.
I received my Ph.D. degree in 2021 from CASIA, supervised by Prof. Tieniu Tan, co-supervised by Prof. Liang Wang and Prof. Wei Wang.
My research interests span visual understanding and generation, including fundamental architectures for computer vision, video understanding, generative models, video and image generation, as well as acceleration and optimization of generative models.
Open Positions
If you are interested in joining our group, feel free to contact me at chenyang.si@nju.edu.cn.
- Ph.D. Students
- Master's Students
- Research Interns
- Research Assistants
For more information, please see this Zhihu post.
Publications

RepVideo: Rethinking Cross-Layer Representation for Video Generation
Chenyang Si, Weichen Fan, Zhengyao Lv, Ziqi Huang, Yu Qiao, Ziwei Liu
arXiv:2501.08994, 2025

Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Weichen Fan, Chenyang Si, Junhao Song, Zhenyu Yang, Yinan He, Long Zhuo, Ziqi Huang, Ziyue Dong, Jingwen He, Dongwei Pan, Yi Wang, Yuming Jiang, Yaohui Wang, Peng Gao, Xinyuan Chen, Hengjie Li, Dahua Lin, Yu Qiao, Ziwei Liu
arXiv:2501.08453, 2025
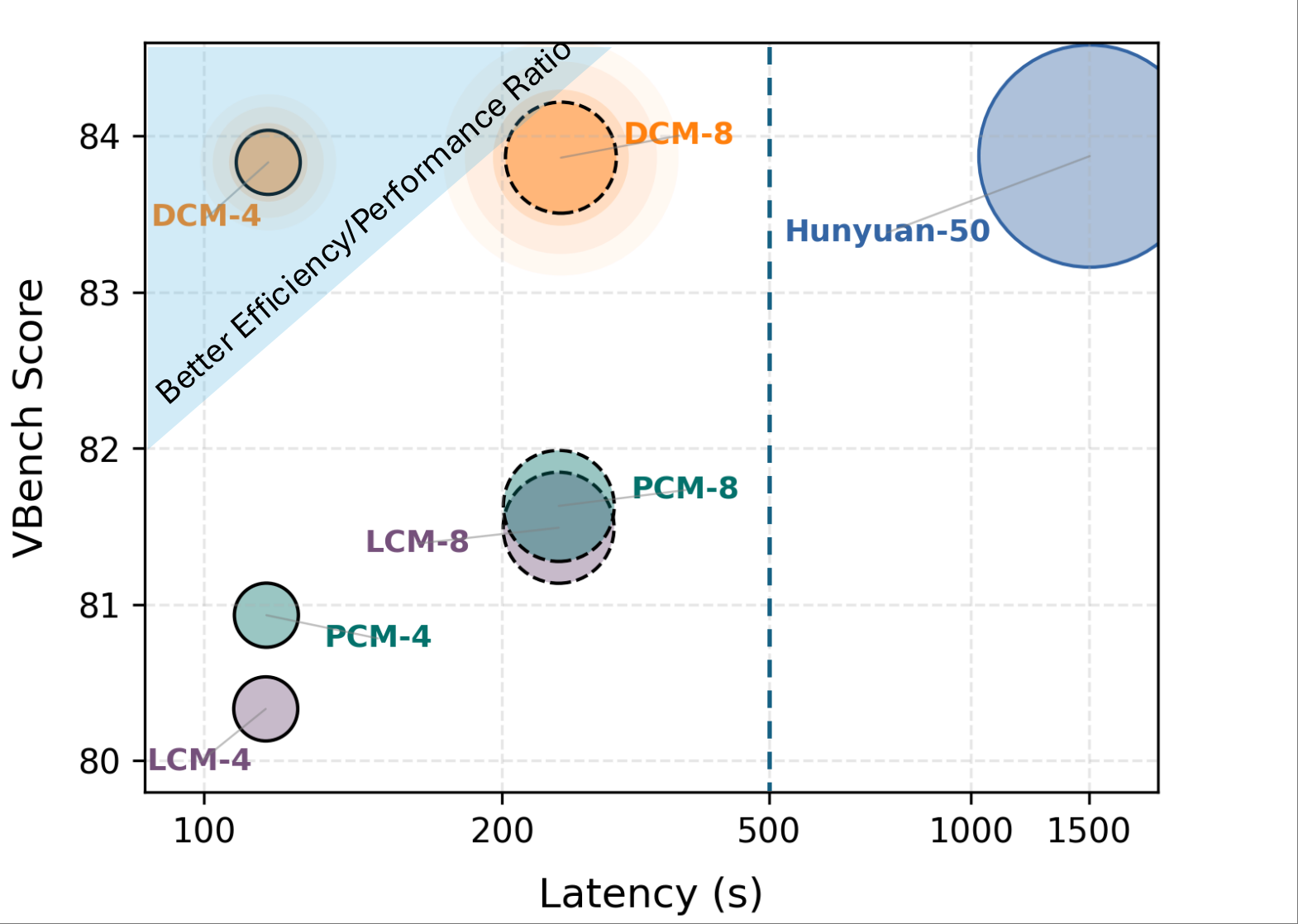
DCM: Dual-Expert Consistency Model for Efficient and High-Quality Video Generation
Zhengyao Lv, Chenyang Si, Tianlin Pan, Zhaoxi Chen, Kwan-Yee K. Wong, Yu Qiao, Ziwei Liu
ICCV, 2025

TACA: Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers
Zhengyao Lv, Tianlin Pan, Chenyang Si, Zhaoxi Chen, Wangmeng Zuo, Ziwei Liu, Kwan-Yee K. Wong
ICCV, 2025
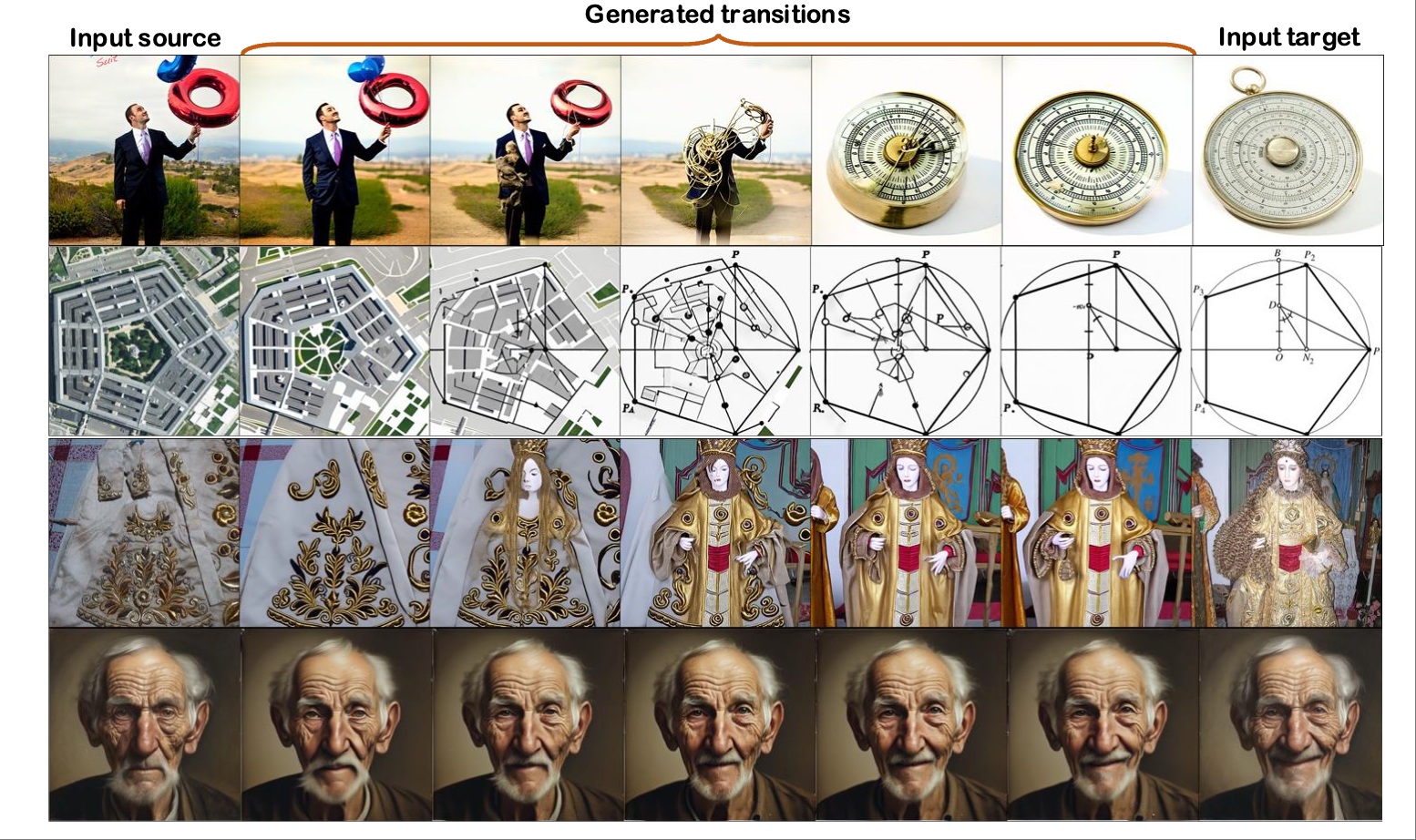
FreeMorph: Tuning-Free Generalized Image Morphing with Diffusion Model
Yukang Cao1, Chenyang Si, Jinghao Wang, Ziwei Liu
ICCV, 2025

Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, Yuan Liu
SIGGRAPH (Conference Track), 2025
(Selected in SIGGRAPH Video Trailer)
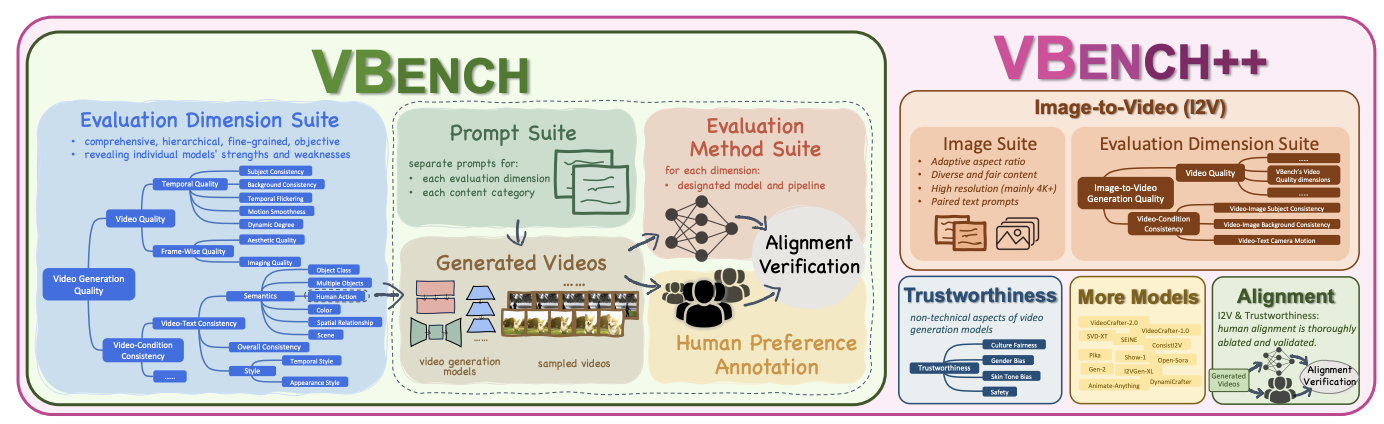
Vbench++: Comprehensive and versatile benchmark suite for video generative models
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
arXiv:2411.13503, 2025

Fastercache: Training-free video diffusion model acceleration with high quality
Zhengyao Lv, Chenyang Si, Junhao Song, Zhenyu Yang, Yu Qiao, Ziwei Liu, Kwan-Yee K Wong
ICLR, 2025

FreeInit: Bridging Initialization Gap in Video Diffusion Models
Tianxing Wu, Chenyang Si, Yuming Jiang, Ziqi Huang, Ziwei Liu
ECCV, 2024

FreeU: Free Lunch in Diffusion U-Net
Chenyang Si, Ziqi Huang, Yuming Jiang, Ziwei Liu
CVPR, 2024
(Oral)

VBench: Comprehensive Benchmark Suite for Video Generative Models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
CVPR, 2024
(Highlight)

VideoBooth: Diffusion-based Video Generation with Image Prompts
Yuming Jiang, Tianxing Wu, Shuai Yang, Chenyang Si, Dahua Lin, Yu Qiao, Chen Change Loy, Ziwei Liu
CVPR, 2024

Towards Language-Driven Video Inpainting via Multimodal Large Language Models
Jianzong Wu, Xiangtai Li, Chenyang Si, Shangchen Zhou, Jingkang Yang, Jiangning Zhang, Yining Li, Kai Chen, Yunhai Tong, Ziwei Liu, Chen Change Loy
CVPR, 2024


Lavie: High-quality video generation with cascaded latent diffusion models
Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, Yuwei Guo, Tianxing Wu, Chenyang Si, Yuming Jiang, Cunjian Chen, Chen Change Loy, Bo Dai, Dahua Lin, Yu Qiao, Ziwei Liu
IJCV, 2024


FSAR: Federated Skeleton-based Action Recognition with Adaptive Topology Structure and Knowledge Distillation
Jingwen Guo, Hong Liu, Shitong Sun, Tianyu Guo, Min Zhang, Chenyang Si
ICCV 2023 (Corresponding author)



Federated Zero-Shot Learning with Mid-Level Semantic Knowledge Transfer
Shitong Sun, Chenyang Si, Shaogang Gong, Guile Wu
Pattern Recognition 2023



Contrast-reconstruction Representation Learning for Self-supervised Skeleton-based Action Recognition
Peng Wang, Jun Wen, Chenyang Si, Yuntao Qian, Liang Wang
TIP 2022


Generalizable Person Re-Identification via Self-Supervised Batch Norm Test-Time Adaption
Ke Han, Chenyang Si, Yan Huang, Liang Wang, Tieniu Tan
AAAI 2022

Few-Shot Learning with Part Discovery and Augmentation from Unlabeled Images
Wentao Chen, Chenyang Si, Wei Wang, Liang Wang, Zilei Wang, Tieniu Tan
IJCAI 2021


Skeleton-Based Action Recognition with Hierarchical Spatial Reasoning and Temporal Stack Learning Network
Chenyang Si, Ya Jing, Wei Wang, Liang Wang, Tieniu Tan
Pattern Recognition 2020

Pose-Guided Multi-Granularity Attention Network for Text-Based Person Search
Ya Jing, Chenyang Si, Junbo Wang, Wei Wang, Liang Wang, Tieniu Tan
AAAI 2020 (Oral)

An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition
Chenyang Si, Wentao Chen, Wei Wang, Liang Wang, Tieniu Tan
CVPR 2019

Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning
Chenyang SiChenyang Si, Ya Jing, Wei Wang, Liang Wang, Tieniu Tan
ECCV 2018

Pose-Based Two-Stream Relational Networks for Action Recognition in Videos
Wei Wang, Jinjin Zhang, Chenyang Si, Liang Wang
Tech report 2018

Multistage adversarial losses for pose-based human image synthesis
Chenyang Si, Wei Wang, Liang Wang, Tieniu Tan
CVPR 2018 (spotlight)
Academic Services
Conference Area Chair
Conference Reviewer
Journal Reviewer